
Note de Lecture - IA - 4

Article en pré-publication sur ArXiV: Language Models are Injective and Hence Invertible par Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, Andrea Santilli, Yannis Panagakis, Emanuele Rodolà.
Résumé et Argument
Les résultats de ce papier sont impressionnants et de nature théorique. Il touche à l’amélioration de la compréhension de ce qu’il se passe quand un modèle, type LLM basé sur le mécanisme d’attention, apprend. Clairement l’apprentissage conduit à un réglage des poids dans un réseau de neurones, mais comme le réseau et la base d’apprentissage ont des dimensions surhumaines, typiquement du niveau de “tout ce qui a été publié sur internet”, il est très difficile de se faire une idée de quel poids représente quoi. Le problème de l’explicabilité de l’IA en général et des réseaux de neurones en particulier est un sujet crucial: en effet de plus en plus ces IA et réseaux sont appelés à, sinon prendre des décisions, au moins aider à la prise de décision dans un spectre de domaines toujours plus large. Savoir pourquoi dans un procès une IA préconnise X plutôt que Y a donc son importance pour motiver un arrêté.
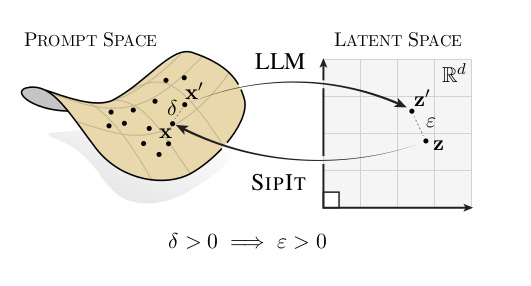
En l’occurrence le titre dévoile toute l’intrigue. Les LLMs sont des structures injectives, signifiant que pour chaque sortie correspond une unique entrée. La démonstration suit un modèle très similaire à ceux qu’on utilise en réécriture : chaque étape d’apprentissage conserve ce caractère injectif ce qui n’est pas évident à première vue car le mécanisme d’attention par exemple n’est pas intrinsèquement injectif. On pourrait donc penser que le modèle fait s’effondrer différentes entrées sur des états équivalents ce qui conduirait à avoir un modèle surjectif. Cela vient de la manière dont les paramètres sont ajustés et l’entrainement réalisé. Il est possible qu’il y ait des collisions mais pour un ensemble de mesure nulle : en gros celui qui entraîne le réseau peut, à la main, créer des collisions ponctuelles (c’est à dire pour des prompts précis), dès qu’un token sera changé dans le prompt la propriété de collision va disparaître.
Les implications théoriques sont nombreuses notamment la démonstration rigoureuse que l’injectivité n’est pas un cas limite vers lequel le modèle convergerait asymptotiquement, mais bien une conséquence directe de ce type particulier d’architecture. Concrètement les auteurs se sont basés sur ce résultat pour construire un algorithme, SIPIT, permettant de reconstruire les prompts à partir des résultats produits par le modèle. SIPIT est un algorithme linéaire, ce qui n’est pas étonnant car les LLMs prennent un temps de réflexion proportionnel à la longueur du prompt —ce qui au passage montre qu’il ne s’agit pas d’intelligence mais bien d’un système d’information— pour construire leurs résultats. Même si l’injectivité et la complexité linéaire ne garantissent pas cette propriété typiquement … la multiplication de nombres premiers et la factorisation (propriété qui est à la base du système RSA).
Le papier comporte également des résultats pratiques de recherche de collisions sur 100k prompts obtenus par tirage aléatoire dans des ensembles de données issus de wikipedia, the pile, C4 et Language model inversion. 4 modèles open sources ont été testés Llama-3.1-8B, Mistral-7B-v0.1, Phi-4-mini-ins, TinyStories-33M. Il n’y a pas eu de collisions détectées. Ils ont aussi testé leur algorithme SIPIT qui donne des résultat meilleur en qualité et en temps de calculs aux propositions HARDPROMPT (qui ne retrouve rien) et BRUTEFORCE qui est une version de SIPIT qui n’utilise pas le gradient (qui retrouve tout mais avec un temps d’éxécution de 4k secondes au lieu de 30 secondes).
Les conclusions sont que ces architectures ne perdent pas d’information au cours de l’entraînement, mais représentent une manière de les coder différente des manières usuelles comme ce serait le cas dans une base de données. L’algorithme SIPIT montre que cet aspect théorique a des implications pratiques directes. Ces résultats ont des implications légales notamment en termes de confidentialité. On ne peut pas dire que le modèle anonymise les données (on peut penser à des informations sur le statut médical d’un patient pour une IA dans le domaine de la santé).
Remarques personnelles
Ce papier renforce mon idée que les IA de type LLMs n’ont pas grand chose avoir avec l’”intelligence” mais sont en fait des techniques qui relèvent plutôt du monde des systèmes d’information. Les LLMs permettent une représentation des données qui peut être interrogée de manière non structurée avec le langage naturel : les prompts, plus besoin d’être un mage de SQL pour interroger une base de données. Cela indique que la direction de la recherche devrait être de chercher à les rendre plus fiables (identifier les sources) plutôt que plus intelligentes (spoiler alerte : elles ne le seront jamais).
Les LLMs passent avec brio le test de Turing. En cela cette technologie nous a aidé à affiner ce que nous entendons par “intelligence” qui reste un terme qui n’est jamais bien défini. Un peu comme en médecine, où la définition de “maladie/être malade” reste élusive. On a souvent des définitions circulaires comme “on malade lorsqu’on n’est plus en bonne santé” mais ce que être en bonne santé signifie n’est pas clair. L’exemple typique est le dopage qui augmente mes capacités d’aujourd’hui au détriment de celles de demain. Suis je malade car mes performance sont moindre que si je ne me dopais pas ? Suis je malade si je suis trop loin de la moyenne ? etc. Le point important est qu’on voit qu’une science dure, issue des mathématiques, prend des traits moins scientifiques avec ces technologies qui sont tellement complexes qu’on finit par les voir comme des phénomènes naturels qu’on étudie alors qu’il s’agit de phénomène complètement artificiels où rien n’est implicite, mais la taille gigantesque de ces outils les rends très difficile à analyser autrement que de manière observationnelle.
Les implications en terme de sécurité sont nombreuses. Par exemple cette idée que le modèle évolue au fur et à mesure des interactions avec les clients devient immédiatement suspecte même si ça pourrait paraître intéressant. J’imagine que nous allons rapidement voir de nouvelles attaques dans ce type de système pour inférer quelles sont les prompts d’autres clients par des canaux cachés. En effet si les interactions sont vues comme un matériel d’apprentissage alors ce papier montre … que rien n’est perdu ni réellement caché.