
Note de Lecture - IA - 5

Article en pré-publication sur ArXiV: Recursive Language Model par Alex Zhang, Tim Kraska et Omar Khattab du MIT.
Résumé et Argument
Ce papier présente les Recursive Language Models (RLMs), une méthode d'inférence générale permettant aux LLMs de traiter des prompts très longs en les déchargeant dans un environnement externe (comme un REPL Python) et en permettant au modèle d’interagir avec ce contenu de manière programmable et récursive. Les auteurs parlent de RLM (R pour Récursif bien sûr).
L’idée fondamentale est qu’au lieu de donner tout le prompt directement au réseau de neurones, celui-ci est placé dans une variable accessible via un environnement d’exécution (REPL Python mais qui reste énigmatique dans le corps de l’article). Le LLM peut ainsi inspecter, décomposer et manipuler le contenu via du code. Le LLM peut se rappeler lui-même de manière récursive sur des sous-parties du prompt, ce qui permet de traiter des contenus bien plus longs que la fenêtre de contexte d’origine.
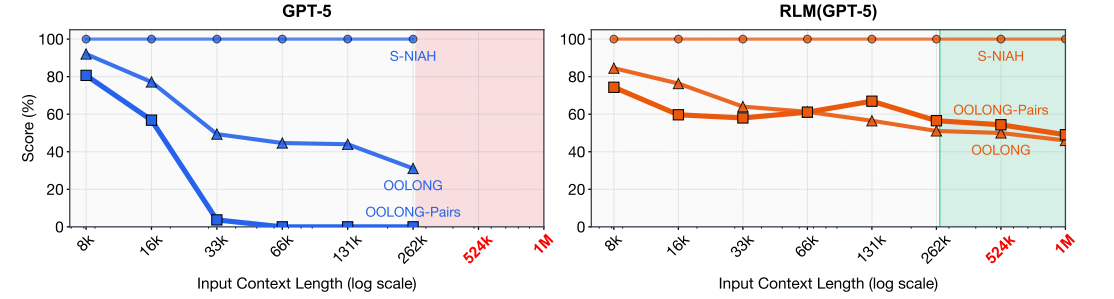
Les résultats que les chercheurs prétendent sont (de manière synthétique et sans critiquer pour le moment ces résultats) :
Passage à l’échelle au-delà de la fenêtre de contexte: les RLMs traitent des inputs jusqu’à 10M+ tokens, soit deux ordres de grandeur au-delà des fenêtres de contexte des LLMs testés (comme GPT-5, limité à ~272K tokens).
Amélioration marquée sur des tâches long-contexte complexes
Performance maintenue malgré une complexité croissante:
Coût maîtrisé (jusqu’à trois fois moins chers que les agents de LLM standard) et souvent inférieur aux méthodes de condensation (même médiane mais plus de variance suivant les requêtes).
Capacités émergentes de raisonnement et de vérification. C’est peut être le point le plus important à discuter.
Limites identifiées dans le papier :
Les RLMs sont plus lents en exécution séquentielle (bloquante).
Ils peuvent générer des appels récursifs excessifs (surtout avec certains modèles comme Qwen3-Coder).
Sur des prompts très courts, le modèle de base peut parfois être plus efficace.
Remarques personnelles
Ca rappelle fortement le Chain of thought et peut se voir dans la continuation des travaux qui cherchent à améliorer cette approche (dont nous avons déjà parlé ici). L’idée est plus ou moins d’automatiser cette décomposition en rappelant récursivement en fonction de la longueur et de la complexité du prompt. La première question qui se pose est : quelle est la limite de la récursion et les RLM peuvent ils rentrer en boucle ? Rien de bien clair dans le papier, sûrement un timeout.
Un point positif est que l’approche est agnostique vis à vis des modèles. On peut ainsi l’utiliser pour Claude, ChatGPT, DeepSeek etc. Il faut juste que le modèle soit en mesure d’éxécuter du code correctement (ici c’est du Python). Ca va dans le sens de l’évolution continuelle de ces modèles qui sont de moins en moins un LLM mais une usine à gaz remplie de cas particuliers. En l’occurrence il y a une sauce magique qui est le REPL qui sert à jauger combien l’agent aura besoin d’information pour résoudre la tâche et voir si les retours sont satisfaisants. La technique REPL qui sert de mémoire externe est une méthode générale.
De plus haut niveau ça montre que les réflexions de Yann LeCun sur le fait que les LLMs ne sont pas le chemin pour l’AGI (si toutefois cette dernière est possible) semblent se concrétiser d’un point de vue expérimental : il faut ajouter des choses autour du LLM pour approfondir le raisonnement et le forcer a raffiner ses réponses, même si ici on est plus sur patch de haut niveau que sur une percée conceptuelle.